1. Object Detection With CNNs
1.1 R-CNN
R-CNN = Selective Search + CNN + SVM
- Input Image
- Extract region proposals
- Compute CNN Features
- Classify regions
Limitation:
- 需要固定输入图像的大小,这限制了输入图像的角度和尺度
- 多阶段的训练:Train CNN ; Train SVM
- 大量的Proposal 框,存储效率低下
- 多余Proposals 和耗费时间
1.2 SPPNet
操作:
- 将特征图划分为
1*12*24*4的区域 - 在每个区域进行最大池化操作
- 最终形成一个
1+4+16个特征块
- 最终形成一个
Improvement:
- 只对整个图像计算一次特征图
- 在任意区域中池化特征以生产 fixed-length representations
Limitation:
仍然是一个多阶段的pipeline:特征提取 -> 网络微调 -> SVM 训练 -> 训练边界框回归
1.3 Fast RCNN
Making the structure end-to-end
ImproveMent:en d -to-end learning via a multi-task loss
Limitation:
- 将每个候选区域划分成7*7个相等的部分
- 对每个区域应用最大池化操作
- 所有的输入都被统一为
7*7的大小
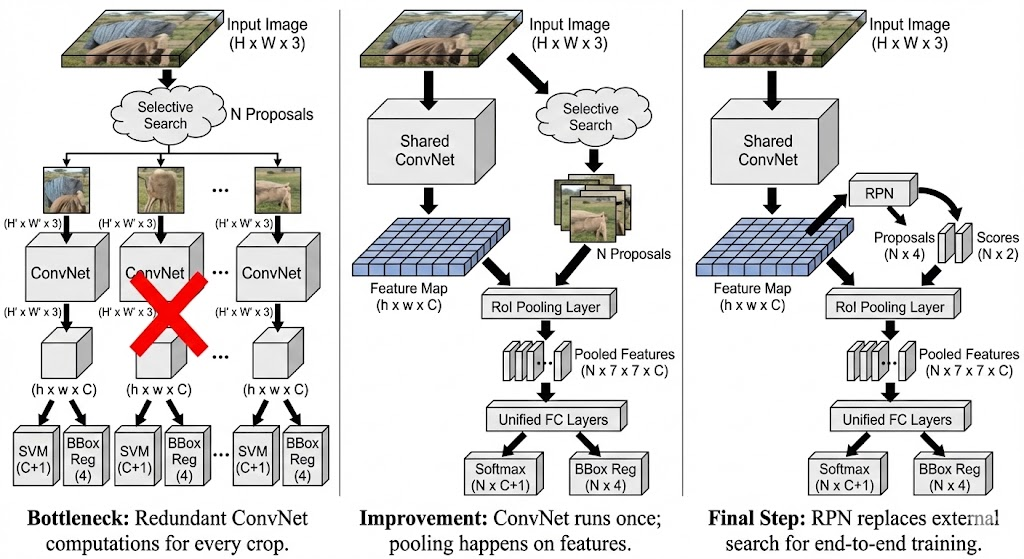
R-CNN vs. Fast R-CNN
| 对比维度 (Improvement) | R-CNN (“Slow” R-CNN) | Fast R-CNN | 核心改进点 |
|---|---|---|---|
| 特征提取方式 (Feature Extraction) | 重复计算: 对每一个候选区域(Region of Interest, RoI)单独截取图像块,并分别送入卷积网络计算特征。 | 共享计算: 整张图像只送入卷积网络一次。使用 RoI Pooling 将不同大小的 RoI 直接映射到特征图上的固定大小区域。 | 避免了对成千上万个 RoI 进行重复的卷积运算,极大提升了效率。 |
| 训练方式 (Training Approach) | 分阶段/独立优化: 分类器(Class)和边界框回归(Bbox)是分开处理的组件(从图中可以看出它们是独立的模块)。 | 多任务损失 (Multi-task loss): 引入多任务损失函数,同时 (Simultaneously) 优化分类任务和边界框回归任务。 | 实现了更统一的优化,不仅简化了流程,还提升了最终的准确率。 |
| 网络结构 (Network Structure) | 松散的组件: 特征提取与后续的分类/回归网络是割裂的,计算存在大量冗余。 | 统一的实体 (Single Entity): 将特征提取网络与分类/回归网络结合为一个整体,共享卷积层。 | 减少了冗余计算,提升了整体计算效率。 |
| 处理对象 (Core Transformation) | Image Proposals: 处理的是原始图像上的切片(Warped image regions)。 | Feature Proposals: 处理的是卷积特征图上的切片。 | 从“处理图像块”进化为“处理特征块”。 |
- RCNN, SPPNet and Fast RCNN rely on selective search
- Region proposal computation is still a bottleneck
1.4 Faster RCNN
Insert Region Proposal Networt(RPN) to predict proposals from features, 通过引入一个微型神经网络 RPN ,直接在特征图上滑动,快速预测哪里可能有物体。
$$
Faster RCNN = Fast RCNN+RPN
$$
1.4.1 RPN
基于预设的 Anchor Box来判断物体在哪里,在特征图的每一个像素点上,都叠放这一组固定形状和大小的框
假设:
- 输入图像大小为 3*640*480, image features=512*20*15
- Anchor Box:三种尺度($128^2,256^2,512^2$ ) ,三种长宽比(1:1,1:2,2:1),总计每个像素点生成 3*3 =9 个Anchor box
两个任务:
任务一:分类
- 目标:判断Anchor Box中是物体还是背景
- 输出:k * 20* 15
任务二:回归
- 目标:Anchor Box只是大概位置,可能不准,网络需要一个修正值,把锚框修正到更贴合真实物体的位置
- 输出: 4k*20*15,因此一个框有坐标$(x,y,w,h)$
| 维度 (Improvement) | Fast R-CNN (及之前的 R-CNN) | Faster R-CNN | 核心改进点 (Description) |
|---|---|---|---|
| 区域建议生成 (Region Proposal) | 依赖外部算法: 使用 Selective Search (选择性搜索) 算法来生成候选框。 | 引入 RPN: 使用 Region Proposal Network (区域建议网络) 在网络内部生成候选框。 | 实现了高效且精准的候选框生成,彻底替代了缓慢的 Selective Search 算法。 |
| 特征共享 (Feature Sharing) | 无共享: 候选框生成步骤(Selective Search)和后续的检测网络是完全独立的,无法共享计算。 | 共享卷积特征: RPN 和 Fast R-CNN 检测网络共享同一组卷积特征图。 | 减少了冗余计算,大幅提升了运行效率。 |
| 网络结构 (Network Structure) | 分离结构: 候选框生成是独立的一步,与检测网络是割裂的。 | 统一网络 (Unified Network): 将 RPN 和 Fast R-CNN 集成到一个统一的网络中。 | 允许同时 (Simultaneous) 进行候选框生成和物体检测,从而显著缩短了推理时间(Inference time)。 |
| 特征层级差异 (Feature Level Difference) | 低级特征: Selective Search 依赖图像的低级特征(如颜色、纹理)来合并区域。 | CNN 特征: RPN 利用深层的 CNN 特征来定位更准确的建议框。 | 深度特征包含语义信息,生成的建议框质量更高。 |
| 训练策略 (Training Approach) | (图片未详细描述 Fast R-CNN 的具体训练,但在上下文中通常是分阶段的) | 两阶段训练 (Two-stage strategy): 1. 先训练 RPN 生成高质量候选框; 2. 再训练 Fast R-CNN 对这些框进行分类和微调。 | 确保两个模块都能被充分优化。 |
1.5 YOLO
1.5.1 Single-Stage Object Detection
传统方法(如 R-CNN): 先在图像上生成无数个候选框(Region Proposals),然后对每个框进行分类。这是一个分类问题。
Single-Stage OD是一个回归问题。它不需要生成候选框,而是直接输入整张图片,让神经网络一次性输出图片中所有物体的位置坐标(Bounding Box)和类别概率。因此分类输出维度是$(C+1) \times K\times20 \times 15$,Box输出维度是$C \times 4K\times20 \times 15$
1.5.2 v1
每个网格需要预测 B 个边界框,每个边界框包含 5 个预测值:
- $x,y$:边界框中心相对于网格边界的偏移量。
- $w,h$:边界框的宽和高(相对于整张图)。
- Confidence:置信度,代表“框里有物体的概率” $\times$ “预测框与真实框的重合度(IoU)”。
同时,每个网格还要预测 C 个类别的条件概率(即如果这里有物体,它是猫、狗还是车的概率)。
1.5.3 Further improvement
- Train longer
- Multiscale backbone:Feature pyramid Network
- Better Backbone:ResNet
- Very big models work better
- Big ensembles, more data, etc..
2. 3D Vision with Deep Learning
主要问题:
- 从单张图片预测3D形状
- 根据3D形状判断物体类别
3D形状的表示方法:
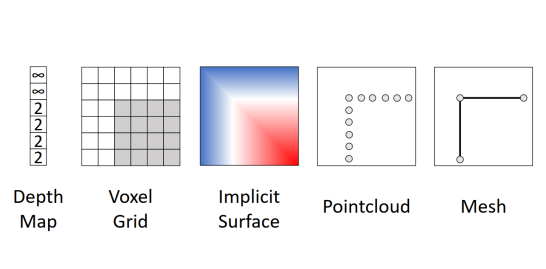
2.1 Depth Map
Depth Map可以给出每个像素到摄像头的距离
RGB image ($3\times H \times w$)+ Depth image($H\times W$) = RGB-D Image(2.5D)
这种数据可以被一些3D传感器直接记录下来
Predicting Depth
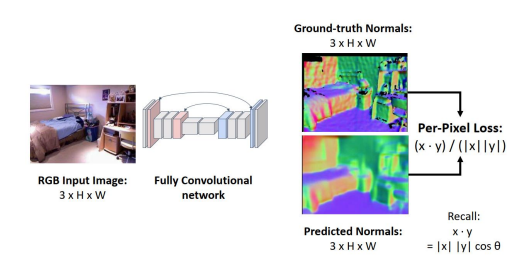
2.2 Surface Normal
表面法线:对于每个像素,表面法线提供了一个向量,表示该像素在世界空间中的物体的法线向量
Predicting Normals
2.3 Voxels
- 用 $V\times V \times V$ 网格表示形状
- (+)概念十分简单,就是一个3D网格
- (-)需要高空间的分辨率来捕捉细小结构
- (-)向高分辨率扩展很困难
Processing voxels Inputs:
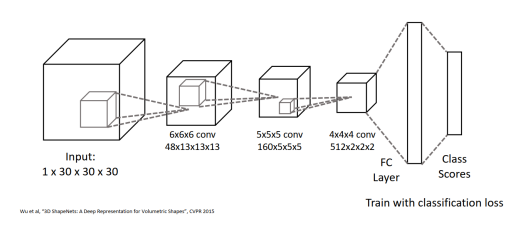
Voxel Problems:Memory Usage
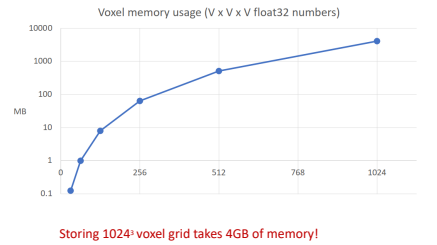
Scaling Voxeds: Oct-Trees
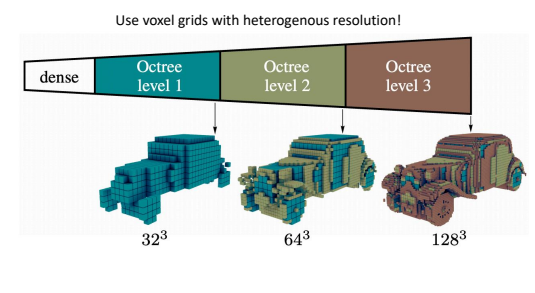
解决方案是使用 “Heterogenous resolution”(非均匀分辨率/异构分辨率)。
- 八叉树原理:
- 想象一个大立方体。如果这个立方体里是“空的”(没有物体),我们就不用管它,只存一个大块。
- 如果这个立方体里“有物体”(比如车的引擎盖),我们就把它切成 8 个 更小的小立方体(这就是“八叉”的由来)。
- 然后对这 8 个小立方体重复上述过程:空的就不管,有细节的继续切分。
- 结果: 我们只在物体表面(需要细节的地方)使用高分辨率的小方块,而在空旷的背景或物体内部使用低分辨率的大方块。这极大地节省了内存
2.4 Point Cloud
- 将形状表示为 3D 空间中的 P 个点的集合
- (+) 可以用很少的点表示细腻的结构
- ( )需要新的结构、损失函数等
- (-) 没有明确表示形状的表面:提取用于渲染或其他应用的网格需要后处理
由于点云数据的无序性和不规则性,主要介绍四种主流的深度学习处理范式:
2.4.1 基于 PointNet 的方法
这是处理点云的开创性工作(引用了 CVPR 2017 的 PointNet 和 NeurIPS 2017 的 PointNet++)。
- 核心思想:将点云视为一个集合(Set),点的顺序不应该影响结果(置换不变性)。
- 处理流程:
- 对每一个点独立运行 MLP(多层感知机)。
- 使用 Max-Pooling(最大池化) 操作将所有点的特征聚合为一个全局特征向量。
- 最后通过全连接层进行分类。
- 特点:直接处理原始点云,简单高效。
2.4.2 基于卷积的方法
- 挑战:点云在空间分布上是不规则的,无法直接使用传统的标准卷积(Grid-based Convolution)。
- 两种解决方案:
- 3D 连续卷积 (Continuous Convolution):在连续空间定义卷积核,邻域点的权重取决于其相对于中心点的空间分布。
- 3D 离散卷积 (Discrete Convolution):在规则网格上定义卷积核,邻域点的权重取决于相对于中心点的偏移量(Offset)。
2.4.3 基于图的方法
- 核心思想:将每一个点或点的区域视为图(Graph)的一个顶点(Vertex)。
- 流程:输入点 $\rightarrow$ 图构建 $\rightarrow$ 特征学习与池化 $\rightarrow$ 输出点。
- 优点:
- 处理不规则数据的能力强。
- 模型通常比较轻量级。
2.4.4 基于 Transformer 的方法
- 核心思想:将每一个点视为一个 Token(类似于自然语言处理中的词向量)。
- 流程:展示了如 “Pyramid Point Transformer” 的架构,包含 Embedding、Transformer 模块、上采样(Upsampling)和 MLP。
- 优点:利用自注意力机制(Self-Attention),能够很好地捕捉点与点之间的全局相关性(Global correlation)。
3. Videos with Deep Learning
定义:视频可以被视为 2D图片 + 时间维度。它是一个4D张量,形状为 $T \times 3 \times H \times W$(时间帧数 $\times$ 通道数 $\times$ 高 $\times$ 宽)。
任务:主要关注 视频分类(Video Classification) 或动作识别(Action Recognition)。
- 图片识别关注的是“物体”(如:猫、鱼)。
- 视频识别关注的是“动作”(如:游泳、跑步、跳跃)。
难点:视频数据量巨大。
- 原始未压缩视频(高清、高帧率)每分钟可达10GB,直接处理对算力要求极高。
解决方案:基于片段(Clips)训练。
- 不使用全长视频,而是截取短片段(Short clips)。
- 降低帧率(Low FPS)和空间分辨率(Low spatial resolution)。
- 测试时:对视频的不同片段运行模型,然后平均预测结果。
A. Single-Frame CNN
- 思路:将视频的每一帧当作独立的图像,用标准的2D CNN进行分类,最后对所有帧的预测结果取平均。
- 评价:这通常是一个非常强劲的基准(Baseline),课件建议“总是先尝试这个方法”。
- 缺点:完全忽略了时间信息(动作的连贯性)。
B. Fusion Methods
为了引入时间信息,研究者尝试融合不同帧的特征:
- 后期融合 (Late Fusion)
- 在两帧相距较远的地方分别提取特征,最后在全连接层(FC)或通过池化(Pooling)进行融合。
- 问题:很难捕捉帧与帧之间的底层运动细节。
- 早期融合 (Early Fusion) :
- 在输入层就将多帧图像在通道维度拼接(Input: $3T \times H \times W$),然后用2D CNN处理。
- 问题:仅靠第一层卷积很难有效处理所有的时间信息。
C. 3D CNN
- 思路:将卷积核扩展到3D(时间 $\times$ 高 $\times$ 宽),同时在空间和时间维度上提取特征。
- 代表模型:C3D
- 被称为“3D CNN中的VGG”。
- 使用 $3\times3\times3$ 的卷积核。
- 优点:能同时建模外观和运动。
- 缺点:计算量非常大(FLOPs 很高),参数多。
D. Two-Stream Networks
- 思路:将“外观”和“运动”分开处理。
- 空间流 (Spatial stream):输入单帧RGB图像,提取外观特征。
- 时间流 (Temporal stream):输入多帧光流 (Optical Flow) 图,提取运动特征。
- 结果:最后融合两个流的结果。在当时(2014年左右)准确率优于 3D CNN。
E. Long-term Temporal Structure
- 问题:上述CNN方法通常只处理几秒钟的短片段,难以理解长视频中的复杂逻辑。
- 解决方案:CNN + RNN
- 利用 LSTM 或其他循环神经网络(RNN)来处理由CNN提取的帧特征序列。
- 也有 Recurrent Convolutional Network(在卷积层之间加入循环连接)。
F. 基于 Transformer 的方法
- 思路:利用 自注意力机制 (Self-attention) 同时处理空间和时间线索。
- 这是较新的趋势(引用了2021年的论文),试图用 Attention 替代传统的卷积或循环结构来理解视频。
总结
视频深度学习的发展路线大致为:
- Single-frame CNN(最简单,效果意外地好)。
- Late/Early Fusion(尝试引入时间信息)。
- 3D CNN(真正的时空特征提取,但计算重)。
- Two-stream(显式利用光流分离运动信息,效果好)。
- CNN + RNN(解决长序列问题)。
- Spatio-temporal Self-attention(Transformer 时代的新方法)。