Deep Convolutional Neural Networks
ConvNets:
- 神经网络包含更多的卷积层用来输出结果
- 大多数使用一个全连接层用来输出 分类 结果
主要任务:
- Define the objective
- What’s the input/output?
- What’s the loss/objective function?
- Create the architecture
- How many conv layers?
- What size are the convolutions?
- How many FC layers?
- Define hyper-parameters
- What is the learning rate?
- Train and evaluate
- How did we do?
- How can we do better?
特定任务设计:
- Network architecture
- Backbone
- Modules
- Loss Function:
- Objective function
- Regularizations
- Training strategy: available label number and format
- Supervised
- Weakly supervised
- Transfer learning
- Self-Supervised learning
CNN Architectures
- Case Studies
- AlexNet
- VGG
- GoogLeNet
- ResNet
- Also ….
- SENet
- Wide ResNet
- ResNeXT
1. AlexNet
根据提供的课件内容(特别是第19, 20, 56, 70页),结合深度学习的通用知识,以下是对 AlexNet 的详细介绍。
1.1 网络架构
AlexNet主要包含 8层 需要训练权重的层(不包括池化层和归一化层):
- 输入 (Input):$227 \times 227 \times 3$ 的RGB图像。
- 总体结构:5个卷积层 (Conv Layers) + 3个全连接层 (Fully Connected Layers)。
- 详细层级设计:
- Conv1:使用非常大的卷积核 $11 \times 11$,步长 (Stride) 为4。
- 这是AlexNet的一个显著特点(大卷积核),后续的VGGNet为了加深网络,才转向了更小的$3 \times 3$卷积核。
- MaxPool1:$3 \times 3$ 滤波器,步长为2(重叠池化)。
- Conv2:$5 \times 5$ 卷积核。
- Conv3, Conv4, Conv5:连续的 $3 \times 3$ 卷积层。
- FC6, FC7:各包含4096个神经元。
- FC8 (Output):1000个神经元,对应ImageNet的1000个类别,最后接Softmax。
- Conv1:使用非常大的卷积核 $11 \times 11$,步长 (Stride) 为4。
1.2 关键创新点与技术细节
- 多GPU训练: 这是因为当时的GPU(GTX 580)显存只有3GB,无法装下整个模型, 作者将网络拆分到两个GPU上运行,仅在特定的层(如Conv3, FC6, FC7)进行跨GPU通信 (Communication across GPUs)。
- ReLU 激活函数:
- AlexNet引入ReLU代替Sigmoid/Tanh,极大地解决了梯度消失问题,加快了训练速度。
1.3 局限性
- 参数效率:AlexNet虽然计算量(Compute)相对较小,但由于拥有巨大的全连接层,它非常耗费内存 (Memory heavy)。
- 大卷积核的劣势:第一层使用了$11 \times 11$的大卷积核。后来的VGGNet(第21页)证明,使用更小的卷积核($3 \times 3$)堆叠出更深的网络,能获得更好的特征表达能力和分类精度。
2. VGG
VGGNet的核心理念可以概括为:“更深的网络,更小的卷积核”。
2.1 核心设计理念:深度至上
- 背景:在AlexNet(8层)之后,研究人员开始探索网络深度对性能的影响。
- 进化:VGG将网络层数显著增加到了 16层 (VGG16) 和 19层 (VGG19)。
- 结果:在ILSVRC 2014比赛中,VGGNet取得了7.3%的Top-5错误率(显著优于前一年冠军ZFNet的11.7%),证明了更深的网络结构能带来更好的层级特征表达能力。
2.2 关键创新:全 3x3 卷积核
VGG最大的特点是摒弃了AlexNet中使用的 11x11 和 5x5 大卷积核,全网统一使用 3x3 的小卷积核。
为什么选择堆叠 3x3 卷积?
等效感受野 (Effective Receptive Field):
- 堆叠 2层 3x3 卷积,有效感受野相当于 1层 5x5 卷积。
- 堆叠 3层 3x3 卷积,有效感受野相当于 1层 7x7 卷积。
- 结论:用小卷积核堆叠依然可以”看”到大的图像区域。
- 更强的非线性表达 (More Non-linearities):
- 使用三个3x3层,意味着会经过 3次 ReLU 激活函数,而使用一个7x7层只有1次。更多的非线性变换让网络能学习更复杂的特征。
参数量更少 (Fewer Parameters):
- 假设输入输出通道数均为 $C$,计算对比如下:
- 1个 7x7 卷积层:参数量 $= 7 \times 7 \times C^2 = 49C^2$
- 3个 3x3 卷积层:参数量 $= 3 \times (3 \times 3 \times C^2) = 27C^2$
- 结论:在保持感受野相同的情况下,参数量减少了约45%。
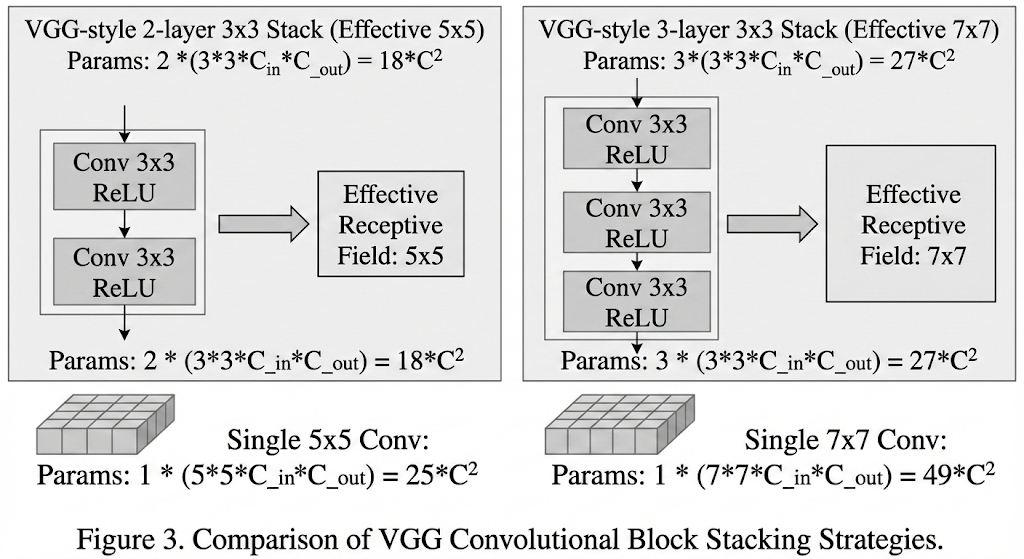
- 假设输入输出通道数均为 $C$,计算对比如下:
2.3 网络架构细节
- 规整的结构:VGG的设计非常模块化。
- 卷积层:全部是 $3 \times 3$ 卷积,Stride=1,Padding=1(保持分辨率不变)。
- 池化层:$2 \times 2$ Max Pooling,Stride=2(分辨率减半)。
- 通道数变化:随着分辨率减半,通道数翻倍(64 $\to$ 128 $\to$ 256 $\to$ 512),见课件第70页总结。
- 全连接层:最后接3个全连接层(4096 $\to$ 4096 $\to$ 1000),这也是AlexNet的遗产。
2.4 优缺点分析
优点:
- 结构极其简单、规整,易于理解和实现(这也是为什么它现在仍常被用作特征提取的Backbone)。
- 分类精度高,泛化能力强。
缺点(:
- 参数量巨大:总参数量高达 1.38亿 (138M),其中大部分集中在最后的全连接层(FC层)。
- 计算昂贵:VGG是所有网络中”圆圈最大”(参数最多)且位置偏右(运算量最大)的模型。
- 内存占用高:前几层卷积产生的Feature Map很大,导致训练和推理时显存占用极高。
VGGNet 确立了现代CNN设计的一个重要标准:使用小的卷积核(3x3)并通过堆叠更深的层数来提高性能。这种设计思想直接影响了后来的 ResNet 等网络架构。
3. GoogLeNet
GoogLeNet(也称为 Inception v1)是2014年ILSVRC图像分类挑战赛的冠军。它由Google团队提出,其设计理念与同年的VGGNet完全不同:不只追求深度,更追求计算效率和参数量的最小化。
- 极高的效率:
- 深度:虽然达到了 22层(比VGG19还深),但参数量极少。
- 参数量:仅有 500万 (5M) 个参数。相比之下,AlexNet有6000万,VGGNet有1.38亿。GoogLeNet的参数量仅为AlexNet的1/12,VGG的1/27。
- 去全连接层:它摒弃了昂贵的全连接层(FC Layers),直接使用全局平均池化 (Global Average Pooling) 输出分类结果,大幅减少了参数。
3.1 Inception 模块
多尺度特征提取 (Multi-scale Cues):
- 传统的网络(如AlexNet, VGG)在每一层只能选择一种卷积核大小。
- Inception模块并行使用 1x1、3x3、5x5 卷积和 3x3 池化。
- 这意味着网络可以在同一层同时捕捉局部的细微特征(1x1, 3x3)和更大范围的抽象特征(5x5),最后通过通道拼接 (Concatenation) 将它们融合。
瓶颈层与1x1卷积 (Bottleneck & 1x1 Conv):
- 问题:直接并行堆叠会导致计算量爆炸。如果直接拼接,输出通道数会剧增,导致下一层的计算量高达8.54亿次运算。
- 解决方案:引入 1x1 卷积 作为”瓶颈层” (Bottleneck Layer)。
- 作用:在进行昂贵的3x3和5x5卷积之前,先用1x1卷积压缩通道数 (Dimension Reduction)。
- 效果:计算量从8.54亿次降至3.58亿次,既保留了特征的空间尺寸,又极大地降低了深度(通道数)和计算成本。
3.2 辅助分类器
Auxiliary Classifiers
- 问题:网络太深(22层),容易出现梯度消失 (Gradient Vanishing),导致浅层网络很难从最后的Loss中获得有效的梯度更新。
- 解决方案:在网络的中间层(浅层位置)引出两个额外的分支,称为辅助分类器(课件第44页)。
- 机制:这些分支在训练时会计算分类Loss,并按一定权重加到总Loss中。这相当于在网络中间”注入”了梯度,强迫浅层网络也能学到有区分度的特征。
- 注:推理(预测)阶段会去掉这些辅助分支。
GoogLeNet的进化路径如下:
- 更深:比VGG更深。
- 更宽:通过Inception模块实现了宽度的增加(多尺度并行)。
- 更高效:利用1x1卷积进行降维,去掉了全连接层。
- 易优化:利用辅助分类器解决深层网络的优化问题。
GoogLeNet证明了:深度神经网络不需要单纯靠堆砌参数,通过精心设计的拓扑结构(Network within a Network),可以用极小的计算代价换取极高的性能。
4. ResNet
ResNet (Residual Network) 是由微软研究院(Kaiming He等)提出的,它是深度学习历史上的一座里程碑,通过引入”残差学习”解决了深层网络的训练难题。
- 深度突破:将网络深度从VGG的19层、GoogLeNet的22层,直接提升到了 152层(甚至可以训练上千层)。
4.1 深层网络的”退化”
退化问题:Degradation Problem
在ResNet提出之前,人们发现一个反直觉的现象):
- 现象:当简单地堆叠更多层(Plain Network)时,随着网络变深,训练误差(Training Error)和测试误差反而都变高了。
- 分析:这不是过拟合(过拟合通常是训练误差低、测试误差高)。
- 结论:这是一个优化问题 (Optimization Problem)。虽然深层网络理论上表达能力更强,但在实际训练中,梯度很难传导,导致深层模型反而更难优化。
4.2 残差学习 (Residual Learning)
为了解决优化难的问题,ResNet提出了残差模块 (Residual Block)。
- 思想实验:如果深层网络的额外层只是做恒等映射 (Identity Mapping)(即输入什么输出什么,不做任何改变),那么深层网络至少应该和浅层网络一样好,不应该变差。
- 结构设计:
- Shortcut/Skip Connection:在堆叠的卷积层旁增加一条直接连通的线,将输入 $x$ 直接加到输出上。
- 公式:网络不再直接学习目标映射 $H(x)$,而是学习残差函数 $F(x) = H(x) - x$。
- 最终输出:$H(x) = F(x) + x$。
- 优势:
- 如果最佳映射就是恒等映射,网络只需要将残差部分 $F(x)$ 的权重学习为0即可,这比直接学习恒等映射容易得多。
- 解决梯度消失:在反向传播时,梯度可以通过 Shortcut 路径无损地传导到浅层,就像走”高速公路”一样,使得超深网络依然可以被有效训练。
4.3 网络架构细节
4.3.1 基础架构
- 全卷积设计:大部分层是 $3 \times 3$ 卷积。
- 尺寸与通道:每当空间分辨率(Feature Map大小)减半(Stride=2)时,滤波器的数量(通道数)就会翻倍,以保持时间复杂度平衡。
- 去全连接:网络末端使用全局平均池化 (Global Average Pooling),最后只接一个FC层输出类别(类似于GoogLeNet),大大减少了参数量。
4.3.2 两种Block设计
- Basic Block(用于ResNet-18, 34):
- 包含两个 $3 \times 3$ 卷积层。
- Bottleneck Block(用于ResNet-50, 101, 152):
- 类似于GoogLeNet的思路,为了在增加深度的同时控制计算量。
- 结构:1x1 Conv (降维) $\to$ 3x3 Conv $\to$ 1x1 Conv (升维)。
- 中间的3x3卷积处理的通道数较少(如64),两头的1x1卷积负责维度的投影。
ResNet的残差连接思想极其重要,它几乎成为了后来所有深度神经网络(包括Transformer, DenseNet等)的标配组件。
5. Improving ResNet
ResNet 之后的改进方案归纳为三个主要方向:提升基数(宽度)、优化梯度传播、以及增强特征交互(注意力机制)。
5.1 ResNeXt:增加基数与宽度
核心理念:Be Wider! (变宽)
- 创新点:引入了 “基数” (Cardinality) 的概念。
- ResNet 是”深”的代表(堆叠层数)。
- Inception 是”宽”的代表(多尺度分支),但结构复杂。
- ResNeXt 结合了两者:它像Inception一样将计算分成多个并行的路径(Split-Transform-Merge),但每一条路径的拓扑结构是完全相同的(简化设计)。
- 具体实现:使用了分组卷积 (Group Convolution)。通过增加并行分支的数量(即基数),在不显著增加参数量和计算复杂度的情况下,提升了模型的表达能力。
5.2 DenseNet:优化梯度与特征重用
核心理念:Feature Reuse (特征重用)
- 机制:密集连接 (Densely Connected)。
- 与ResNet的”元素级相加” ($H(x) = F(x) + x$) 不同,DenseNet 采用 通道拼接 (Concatenation)。
- 网络中的每一层都直接与后面所有层相连。第 $L$ 层的输入是前面 $0$ 到 $L-1$ 所有层输出的拼接。
- 优势:
- 极致的梯度流动:梯度可以直接从Loss传到任何一层,进一步缓解了梯度消失。
- 特征重用:后面的层可以直接使用前面提取的特征,减少了冗余学习。
- 效果:一个较浅的 DenseNet-50 在性能上可以超越更深的 ResNet-152。
5.3 Attention:增强特征交互与自适应
这一方向旨在让网络自动学习”哪些特征更重要”。
5.3.1 A. SENet (Squeeze-and-Excitation Networks)
- 核心模块:SE Block (特征重标定)。
- 步骤:
- Squeeze (压缩):通过全局平均池化 (Global Avg Pooling) 压缩空间信息,得到通道级的全局特征。
- Excitation (激励):使用两个全连接层 (FC Layers) 学习每个通道的权重(重要性)。
- Reweight (重加权):将学到的权重乘回原始特征图。
- 意义:让网络学会关注重要的通道,抑制不重要的通道(Channel-wise Attention)。
5.3.2 B. ResNeSt (Split-Attention Networks)
- 核心:结合了 ResNeXt 的多路径思想和 SENet 的注意力思想。
- 机制:Split-Attention。
- 将特征图分组(Cardinality)。
- 在每一组内部应用通道注意力机制(捕捉跨通道的特征相关性)。
- 这使得不同分支能够学习互补的线索,进一步提升了表示能力。
提升网络表示能力的三个关键维度:
- 提升基数 (Improve Cardinality):让网络更宽、分支更多(代表作:ResNeXt)。
- 优化与连接 (Ease Optimization):让梯度更容易回传,加强层间连接(代表作:DenseNet)。
- 增强交互与自适应 (Improve Interaction & Adaptivity):引入注意力机制,让网络自适应地调整特征权重(代表作:SENet, ResNeSt)。
6. Efficient Networks
Efficient Networks(高效网络) 的设计目标是在保证精度的前提下,大幅减少参数量和计算量,以便在移动端设备(如手机、嵌入式设备)上运行。
课件重点介绍了三种代表性的高效网络方案:MobileNets、ShuffleNet 和 EfficientNet。
6.1 MobileNets: 深度可分离卷积
核心理念:将卷积拆解,分步进行。
- 背景:由Google在2017年提出 (Howard et al.)。
- 核心创新:深度可分离卷积 (Depthwise Separable Convolution)
- 标准卷积 (Standard Convolution):同时处理空间信息(长宽)和通道信息(Channel)。计算量约为 $9C^2HW$(假设是3x3卷积)。
- 深度可分离卷积:将标准卷积分解为两步:
- Depthwise Convolution (逐通道卷积):每个卷积核只处理一个输入通道,提取空间特征。计算量为 $9CHW$。
- Pointwise Convolution (逐点卷积):即 1x1 卷积,用于融合不同通道的信息。计算量为 $C^2HW$。
- 效果:总计算量变为 $9CHW + C^2HW$。相比标准卷积,计算量大幅下降,但精度损失很小。
- 关键点:课件指出,MobileNet与其他网络的主要区别在于跨通道交互 (Cross-channel interaction) 的位置和数量。
6.2 ShuffleNet: 通道混洗
核心理念:解决分组卷积的信息阻塞问题。
- 背景:由Face++ (Zhang et al.) 在CVPR 2018提出。
- 动机:
- 分组卷积 (Group Convolution)(如ResNeXt中使用)可以减少计算量,但存在一个缺陷:不同组之间的信息是不流通的(No cross talk),这限制了特征的表达能力。
- 深度卷积 (Depth-wise conv) 其实就是分组数等于通道数时的特例。
- 核心创新:Channel Shuffle (通道混洗)
- 在分组卷积之后,通过”混洗”操作,将不同组的通道打乱并重组。
- 这样,下一层的分组卷积就能接收到来自上一层不同组的信息,实现了跨组信息交互,在保持低计算量的同时提升了精度。
6.3 EfficientNet: 复合缩放
核心理念:聪明的启发式缩放规则 (Smart Heuristic)。
- 背景:Tan and Le (2019) 提出。
- 问题:以往为了提升性能,人们通常单一地增加网络的深度(ResNet)、宽度(WideResNet)或输入图像的分辨率。
- 核心创新:复合缩放 (Compound Scaling)
- 核心思想:同时、平衡地缩放网络的宽度 (Width)、深度 (Depth) 和 分辨率 (Resolution)。
- 通过搜索一组最优的复合系数 ($\alpha, \beta, \gamma$),在给定的计算资源限制下(Target Memory & FLOPs),获得最好的性能。
- 对比:相比于昂贵的神经架构搜索(NAS),这种基于规则的智能缩放有时效果更好且更易实现。
为了提升效率(Improve the efficiency),主要的技术路径包括:
- Depthwise Conv (MobileNet):拆分空间与通道计算。
- Group Conv (ShuffleNet/ResNeXt):通过分组减少连接密度,并配合Channel Shuffle。
- NAS / Heuristic Rule (EfficientNet):自动化搜索或使用复合缩放规则来寻找最优架构。