1 Motivation
- Multi-view cameras在深度估计、恶劣环境下不稳定
- 以往的方法雷达与摄像头的特征融合方法简单,存在视角\方位不对齐,沿用LiDAR 的编码器并不适合雷达
2 Framework
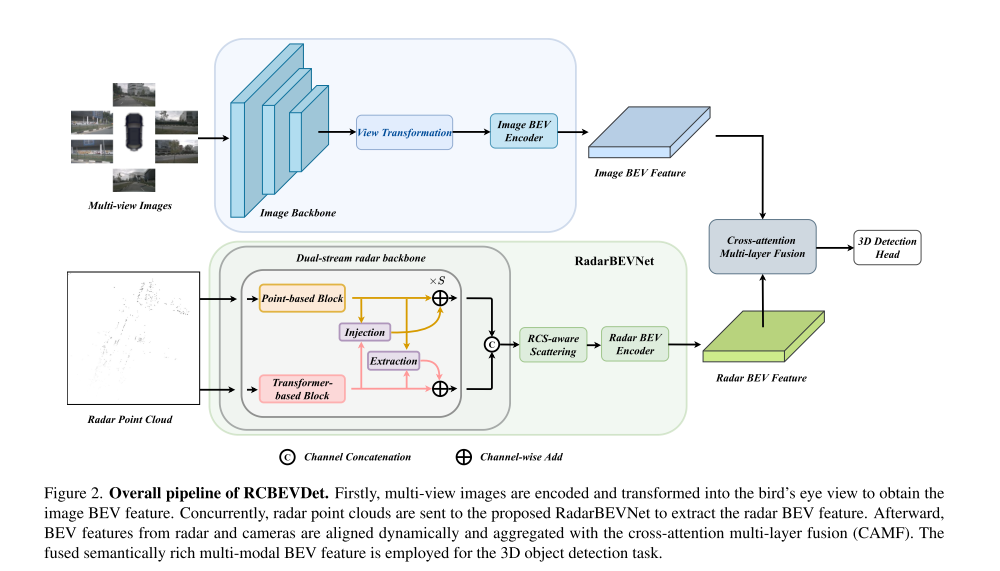
2.1 RadarBEVNet
RadarBEVNet 的作用就是高效提取雷达的特征,有两个组件,分别是是 the dual-stream radar backbone 和 the RCS-aware BEV encoder。前者主要用于雷达特征的初步提取,后者对提取的特征进行再处理。
2.1.1 Dual-stream radar backbone
Dual-stream radar backbone 有S个阶段循环,每个阶段有 point-based block 和 transformer-based block ,后面还有一个module用来对齐两个block的特征后,再进入下一个阶段。
2.1.1.1 Point-based Block
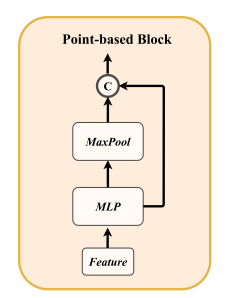
作用:用来学习雷达的局部特征
结构:
输入:Feature(雷达点的初始特征)
MLP
- 对每个点独立地做多层感知机 (MLP) 投影和非线性变换。
- 作用:提升维度并学习局部几何与强度特征。
MaxPool
- 在当前局部点集上做全局最大池化,得到该集合的全局上下文向量。
- 作用:捕获整体形状或分布信息,补充给每个点
拼接与残差:
模仿 PointNet,将全局特征反馈给每个点,以增强点特征的判别力
拼接后的结果通过残差连接返回,用于后续注入/抽取模块或 BEV 投影
公式表达:
$$
f = Concat[MLP(f),MaxPool(MLP(f))]
$$
2.1.1.2 Transformer-bases Block
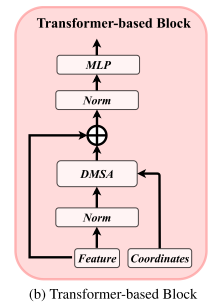
由于自动驾驶场景广泛,标准的自注意力机制可能会使模型具有挑战,因此提出了DMSA,在模型早期训练迭代的时候,聚合相邻信息,从而促进模型的收敛。
具体而言,在给定N个雷达点的坐标情况下,我们首先计算所有点之间的两两距离 $D \in R^{N \times N}$ ,然后生成两两距离 $D$ 的 类高斯权重图 $G$ :
$$
G_{i,j}=exp(-D^2_{i,j}/\sigma^2)
$$
其中,σ是控制类高斯分布宽度的可学习参数。本质上,类似高斯的权重图G将高权重赋予靠近该点的空间位置,而将低权重赋予远离该点的位置。生成的权重G调制注意机制如下:
$$
\begin{eqnarray}
DMSA(Q,K,V)&=&Softmax(\frac{QK^T}{\sqrt{d}}+\log{G})V \
&=& Softmax(\frac{QK^T}{\sqrt{d}}-\frac{1}{\sigma^2}D^2)V
\end{eqnarray}
$$
为了确保 DMSA 可以退化为普通的自注意力机制,在训练过程中将$\frac{1}{\sigma}$ 替换为一个可训练参数 β。 当 β = 0 时,DMSA 就退化为标准自注意力。同时研究了多头 DMSA,其中每个注意力头都拥有独立的 $\beta _i$,用以控制 DMSA 的感受野范围。多头注意力表示为 : $MultiHeadDMSA(Q,K,V)= Concat[head_1,head_2,\cdots ,head_H0]$ ,其中:
$$
\begin{eqnarray}
head_i &=& DMSA(Q_i,K_i,V_i) \
&=&Softmax(\frac{Q_iK_i^T}{\sqrt{d_i}}-\beta _iD^2)V_i
\end{eqnarray}
$$
输入:Feature + Coordinates
- Feature:上一个阶段输出的点特征。
- Coordinates:点的空间坐标,用于计算点间距离(DMSA 需要)。
2.1.1.3 Injection and Extraction
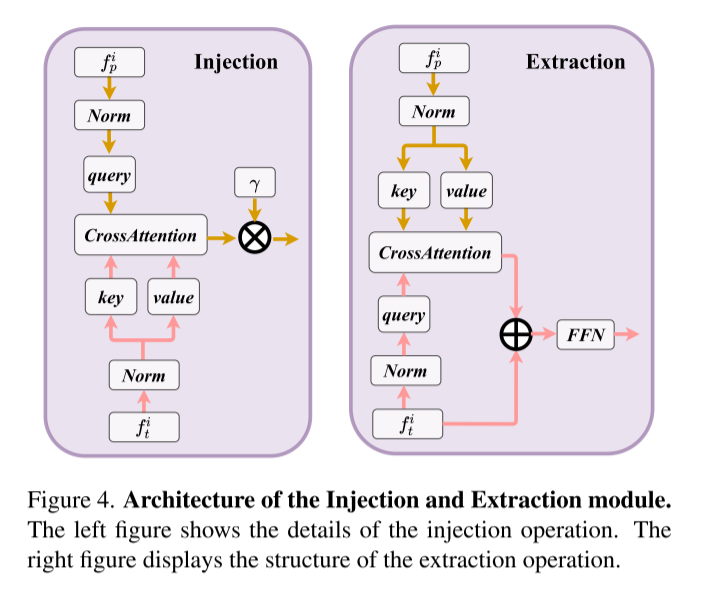
引入交叉注意的注入和提取模块,更好的交互来自两个不同主干网络的雷达特征。如下:
其中LN是层范数,$\gamma$ 是可学习的比例参数,FFN 是前馈网络。$f_p^i$ 表示第 $i$ 次迭代过程中的point特征,$f_t^i$ 表示第$i$ 次迭代过程中的transformer特征
- Injection——将transformer特征注入point
$$
f_p^i = f_p^i+ \gamma \times CrossAttention(LN(f_p^i),LN(f_t^i))
$$
- Extraction——transformer提取point的特征
$$
f_t^i = FFn(f_t^i+ \gamma \times CrossAttention(LN(f_t^i),LN(f_p^i)))
$$
2.1.2 RCS-aware BEV encoder
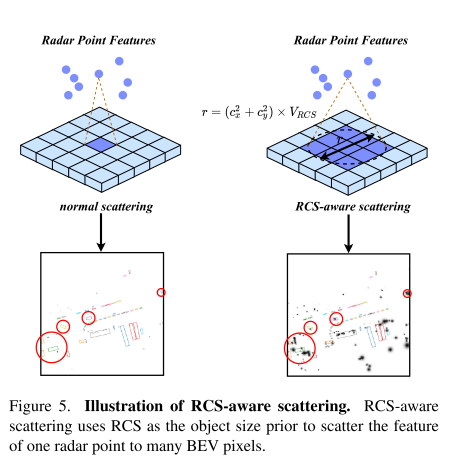
- 解决的问题:传统的雷达BEV编码器产生的特征是稀疏的,大多数像素的特征为0。常见的解决方案是增加BEV编码层的数量,但是这同样导致小特征被背景特征平滑。
- 提出方案:较大的物体产生较强的雷达反射波,从而产生较大的RCS测量,RCS可以提供物体的大小测量,为RCS感知散射操作将雷达的特征分散到多个像素,而不是一个像素。最后利用类高斯分布的BEV权重将这些特征聚合起来。
2.2 CAMF
2.2.1 双向可变形跨注意力
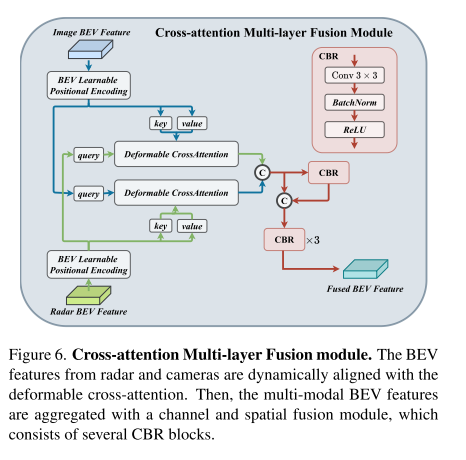
解决的问题:雷达点云会受到方位误差的影响,因此雷达传感器可以获得物体边界外的雷达点,RadarBEVNet生成的雷达特征可以分配给相邻的BEV网格,导致相机和雷达的BEV特征不对准。
提出方案:使用CAMF来动态对齐多通道特征。未对准的雷达点偏移与真实位置有一小段距离,通过可变形交叉注意力机制来捕捉这种偏移。同时将计算复杂度从$O(H^2W^2C)$ 降低到 $O(HWC^2K)$ ,其中K是点每个查询点采样的关键点数量。计算公式如下:
$$
\begin{eqnarray}
DeformAttn(z_{q_r},P_{q_r},F_c) = \sum_{m=1}^{M}W_m[\sum_{k=1}^K A_{mqk}\cdot W’m F_c(p{q_r}+\Delta p_{mqk})]
\end{eqnarray}
$$
其中m索引头部注意力,$k$ 索引关键字采用, $K$ 表述采样关键字总数,$\Delta p_{mqk}$ 表示采样的偏移量,$A_{mqk}$ 表示计算的注意力权重,$F_c$ 表述摄像头特征,$F_r$ 表示雷达特征,当其中一个特征作为query的时候,另一个作为key和value,最后特征表示为:
$$
\begin{align}
F_c &\gets \text{DeformAttn}(z_{q_r}, P_{q_r}, F_c) \
F_r &\gets \text{DeformAttn}(z_{q_c}, P_{q_c}, F_r)
\end{align}
$$
2.2.2 多层融合(Multi-layer Fusion)
- 对齐后的两个特征拼接,拼接后的特征输入到CBR块,共有三个CBR,获得融合特征。
- CBR :Conv、Batch Normalization、ReLU
3. Experiments
3.1 Comparison experiments
-训练策略:两阶段。先单独训练相机流;再训练雷达-相机融合,并冻结相机流参数。共 12 epochs,
AdamW 优化;图像与雷达均做数据增强;CBGS 类别均衡采样。推理在 RTX3090、FP16、batch=1 下计时。
基础配置:消融基线使用 ResNet-50 相机骨干,图像 256×704,BEV 128×128。
主组件叠加:在 BEVDepth 上依次加入:多帧 BEV 累积(时序)→ 雷达 backbone(PointPillars / RadarBEVNet)→ CAMF →(可选)Temporal Supervision 逐帧监督。各组件均带来稳定增益。
实验结果:
NUScenes Results
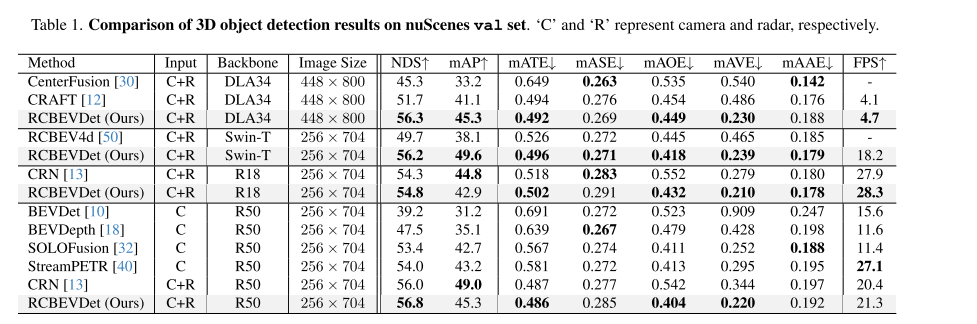
- val 集上,NDS和mAVE的性能明显优于其他方法,在提高准确率的同时降低了速度误差。
- FPS的指标也具有一定的性能优势
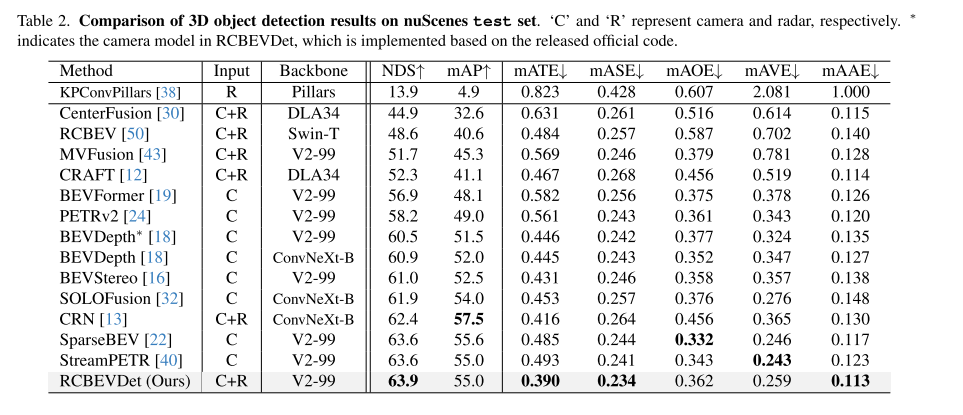 test集上的结果表明,我们可以用更强的backbone来增加RCBEVDet的性能。
test集上的结果表明,我们可以用更强的backbone来增加RCBEVDet的性能。VoD Results(VoD:4D毫米波数据集)
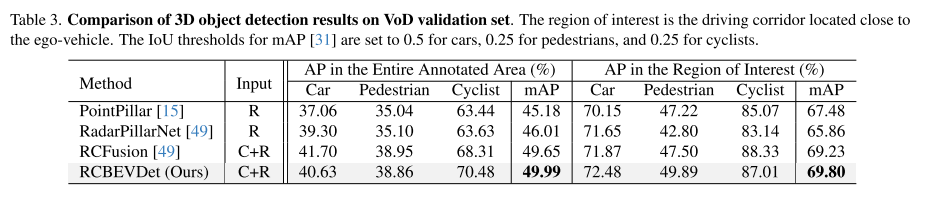 在整个区域,RCBEVDet超过RCFusion 0.34MAP。对于感兴趣的区域,RCBEVDet也以69.80 MAP实现了最先进的结果。
在整个区域,RCBEVDet超过RCFusion 0.34MAP。对于感兴趣的区域,RCBEVDet也以69.80 MAP实现了最先进的结果。
3.2 Ablation Studies
在nuScenes Val集合上进行消融研究,以分析RCBEVDet格部分的效果。采用R50主干、256×704图像大小、128×128 Bev大小的RCBEVDet作为基线模型
3.2.1 Main compnents
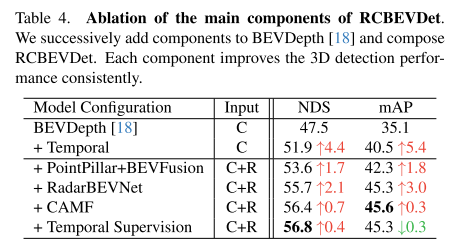
通过想BEVDepth不断添加组件来组成RCBEVDet,具体的性能如图所示。其中Temporal Supervision表示对之前的历史帧和现在的帧进行监督。
3.2.2 RadarBEVNet

- 直接添加transformer backbone带来的性能微不足道,原因是两者的特征没有更好的融合,因此后续引入的注入与提取模块带来了很大的提升
3.2.3 CAMF
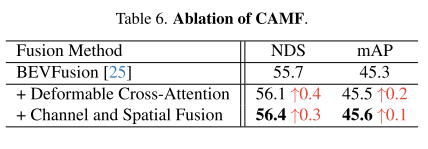
3.3 Robustness
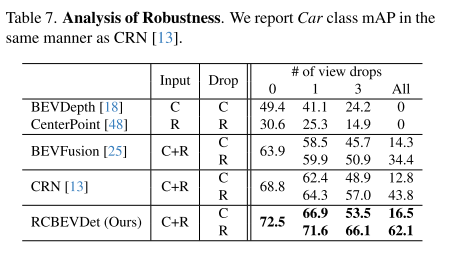
- 在训练和测试中 随机丢弃某些相机视角或雷达帧。对比 RCBEVDet 与其它融合方法(如 CRN、BEVFusion)的性能下降幅度。
4. personal Summary
- Injection 和 Extraction,作者在添加 Transformer-based Block后取得性能提升其实并没有很大,但是注意到了问题在于特征没有对齐,而不是添加的Block不能很好的学习和提取特征。因此个人认为这个模块具有很大意义。
- RCS-aware BEV encoder,解决的传统方法使用 LiDAR编码器遇到的稀疏特征问题,巧妙利用了雷达的RCS的特性,将点特征分散到相邻的像素中去。
- **CAMF:**利用可变形注意力机制,将雷达特征与图像特征对齐,解决雷达特征偏移的问题,更好的融合特征,同时降低了复杂度,能够兼顾特征融合和计算复杂度,我认为这是这个工作的一个很大亮点。



